
Java and XSLT
By Eric M. BurkeSeptember 2001
0-596-00143-6, Order Number: 143-6
528 pages, $39.95
|
|
|
|
|
Java and XSLTBy Eric M. BurkeSeptember 2001 0-596-00143-6, Order Number: 143-6 528 pages, $39.95 |
Chapter 5
XSLT Processing with JavaSince many of the XSLT processors are written in Java, they can be directly invoked from a Java application or servlet. Embedding the processor into a Java application is generally a matter of including one or two JAR files on the CLASSPATH and then invoking the appropriate methods. This chapter shows how to do this, along with a whole host of other programming techniques.
When invoked from the command line, an XSLT processor such as Xalan expects the location of an XML file and an XSLT stylesheet to be passed as parameters. The two files are then parsed into memory using an XML parser such as Xerces or Crimson, and the transformation is performed. But when the XSLT processor is invoked programmatically, you are not limited to using static files. Instead, you can send a precompiled stylesheet and a dynamically generated DOM tree directly to the processor, or even fire SAX events as processor input. A major goal is to eliminate the overhead of parsing, which can dramatically improve performance.
This chapter is devoted to Java and XSLT programming techniques that work for both standalone applications as well as servlets, with a particular emphasis on Sun's Java API for XML Processing (JAXP) API. In Chapter 6, we will apply these techniques to servlets, taking into account issues such as concurrency, deployment, and performance.
A Simple Example
Let's start with perhaps the simplest program that can be written. For this task, we will write a simple Java program that transforms a static XML data file into HTML using an XSLT stylesheet. The key benefit of beginning with a simple program is that it isolates problems with your development environment, particularly CLASSPATH issues, before you move on to more complex tasks.
Two versions of our Java program will be written, one for Xalan and another for SAXON. A JAXP implementation will follow in the next section, showing how the same code can be utilized for many different processors.
CLASSPATH Problems
The Design
The design of this application is pretty simple. A single class contains a
main( )method that performs the transformation. The application requires two arguments: the XML file name followed by the XSLT file name. The results of the transformation are simply written toSystem.out. We will use the following XML data for our example:<?xml version="1.0" encoding="UTF-8"?><message>Yep, it worked!</message>The following XSLT stylesheet will be used. It's output method is
text, and it simply prints out the contents of the<message>element. In this case, the text will beYep, it worked!.<?xml version="1.0" encoding="UTF-8"?><xsl:stylesheetversion="1.0"xmlns:xsl="http://www.w3.org/1999/XSL/Transform"><xsl:output method="text" encoding="UTF-8"/><!-- simply copy the message to the result tree --><xsl:template match="/"><xsl:value-of select="message"/></xsl:template></xsl:stylesheet>Since the filenames are passed as command-line parameters, the application can be used with other XML and XSLT files. You might want to try this out with one of the president examples from Chapters and 3.
Xalan 1 Implementation
The complete code for the Xalan implementation is listed in Example 5-1. As comments in the code indicate, this code was developed and tested using Xalan 1.2.2, which is not the most recent XSLT processor from Apache. Fully qualified Java class names, such as
org.apache.xalan.xslt.XSLTProcessor, are used for all Xalan-specific code.TIP: A Xalan 2 example is not shown here because Xalan 2 is compatible with Sun's JAXP. The JAXP version of this program works with Xalan 2, as well as any other JAXP compatible processor.
Example 5-1: SimpleXalan1.java
package chap5;import java.io.*;import java.net.MalformedURLException;import java.net.URL;import org.xml.sax.SAXException;/*** A simple demo of Xalan 1. This code was originally written using* Xalan 1.2.2. It will not work with Xalan 2.*/public class SimpleXalan1 {/*** Accept two command line arguments: the name of an XML file, and* the name of an XSLT stylesheet. The result of the transformation* is written to stdout.*/public static void main(String[] args)throws MalformedURLException, SAXException {if (args.length != 2) {System.err.println("Usage:");System.err.println(" java " + SimpleXalan1.class.getName( )+ " xmlFileName xsltFileName");System.exit(1);}String xmlFileName = args[0];String xsltFileName = args[1];String xmlSystemId = new File(xmlFileName).toURL().toExternalForm( );String xsltSystemId = new File(xsltFileName).toURL().toExternalForm( );org.apache.xalan.xslt.XSLTProcessor processor =org.apache.xalan.xslt.XSLTProcessorFactory.getProcessor( );org.apache.xalan.xslt.XSLTInputSource xmlInputSource =new org.apache.xalan.xslt.XSLTInputSource(xmlSystemId);org.apache.xalan.xslt.XSLTInputSource xsltInputSource =new org.apache.xalan.xslt.XSLTInputSource(xsltSystemId);org.apache.xalan.xslt.XSLTResultTarget resultTree =new org.apache.xalan.xslt.XSLTResultTarget(System.out);processor.process(xmlInputSource, xsltInputSource, resultTree);}}The code begins with the usual list of imports and the class declaration, followed by a simple check to ensure that two command line arguments are provided. If all is OK, then the XML file name and XSLT file name are converted into system identifier values:
String xmlSystemId = new File(xmlFileName).toURL().toExternalForm( );String xsltSystemId = new File(xsltFileName).toURL().toExternalForm( );System identifiers are part of the XML specification and really mean the same thing as a Uniform Resource Identifier (URI). A Uniform Resource Locator (URL) is a specific type of URI and can be used for methods that require system identifiers as parameters. From a Java programming perspective, this means that a platform-specific filename such as C:/data/simple.xml needs to be converted to file:///C:/data/simple.xml before it can be used by most XML APIs. The code shown here does the conversion and will work on Unix, Windows, and other platforms supported by Java. Although you could try to manually prepend the filename with the literal string
file:///, that may not result in portable code. The documentation forjava.io.Fileclearly states that itstoURL( )method generates a system-dependent URL, so the results will vary when the same code is executed on a non-Windows platform. In fact, on Windows the code actually produces a nonstandard URL (with a single slash), although it does work within Java programs: file:/C:/data/simple.xml.Now that we have system identifiers for our two input files, an instance of the XSLT processor is created:
org.apache.xalan.xslt.XSLTProcessor processor =org.apache.xalan.xslt.XSLTProcessorFactory.getProcessor( );
XSLTProcessoris an interface, andXSLTProcessorFactoryis a factory for creating new instances of classes that implement it. Because Xalan is open source software, it is easy enough to determine thatXSLTEngineImplis the class that implements theXSLTProcessorinterface, although you should try to avoid code that depends on the specific implementation.The next few lines of code create
XSLTInputSourceobjects, one for the XML file and another for the XSLT file:org.apache.xalan.xslt.XSLTInputSource xmlInputSource =new org.apache.xalan.xslt.XSLTInputSource(xmlSystemId);org.apache.xalan.xslt.XSLTInputSource xsltInputSource =new org.apache.xalan.xslt.XSLTInputSource(xsltSystemId);
XSLTInputSourceis a subclass oforg.xml.sax.InputSource, adding the ability to read directly from a DOMNode.XSLTInputSourcehas the ability to read XML or XSLT data from a system ID,java.io.InputStream,java.io.Reader,org.w3c.dom.Node, or an existingInputSource. As shown in the code, the source of the data is specified in the constructor.XSLTInputSourcealso has ano-argconstructor, along with get/set methods for each of the supported data source types.An instance of
XSLTResultTargetis created next, sending the result of the transformation toSystem.out:org.apache.xalan.xslt.XSLTResultTarget resultTree =new org.apache.xalan.xslt.XSLTResultTarget(System.out);In a manner similar to
XSLTInputSource, theXSLTResultTargetcan also be wrapped around an instance oforg.w3c.dom.Node, anOutputStreamorWriter, a filename (not a system ID!), or an instance oforg.xml.sax.DocumentHandler.The final line of code simply instructs the processor to perform the transformation:
processor.process(xmlInputSource, xsltInputSource, resultTree);SAXON Implementation
For comparison, a SAXON 5.5.1 implementation is presented in Example 5-2. As you scan through the code, you will notice the word "trax" appearing in the Java packages. This is an indication that Version 5.5.1 of SAXON was moving towards something called Transformation API for XML (TrAX). More information on TrAX is coming up in the JAXP discussion. In a nutshell, TrAX provides a uniform API that should work with any XSLT processor.
Example 5-2: SimpleSaxon.java
package chap5;import java.io.*;import java.net.MalformedURLException;import java.net.URL;import org.xml.sax.SAXException;/*** A simple demo of SAXON. This code was originally written using* SAXON 5.5.1.*/public class SimpleSaxon {/*** Accept two command line arguments: the name of an XML file, and* the name of an XSLT stylesheet. The result of the transformation* is written to stdout.*/public static void main(String[] args)throws MalformedURLException, IOException, SAXException {if (args.length != 2) {System.err.println("Usage:");System.err.println(" java " + SimpleSaxon.class.getName( )+ " xmlFileName xsltFileName");System.exit(1);}String xmlFileName = args[0];String xsltFileName = args[1];String xmlSystemId = new File(xmlFileName).toURL().toExternalForm( );String xsltSystemId = new File(xsltFileName).toURL().toExternalForm( );com.icl.saxon.trax.Processor processor =com.icl.saxon.trax.Processor.newInstance("xslt");// unlike Xalan, SAXON uses the SAX InputSource. Xalan// uses its own class, XSLTInputSourceorg.xml.sax.InputSource xmlInputSource =new org.xml.sax.InputSource(xmlSystemId);org.xml.sax.InputSource xsltInputSource =new org.xml.sax.InputSource(xsltSystemId);com.icl.saxon.trax.Result result =new com.icl.saxon.trax.Result(System.out);// create a new compiled stylesheetcom.icl.saxon.trax.Templates templates =processor.process(xsltInputSource);// create a transformer that can be used for a single transformationcom.icl.saxon.trax.Transformer trans = templates.newTransformer( );trans.transform(xmlInputSource, result);}}The SAXON implementation starts exactly as the Xalan implementation does. Following the class declaration, the command-line parameters are validated and then converted to system IDs. The XML and XSLT system IDs are then wrapped in
org.xml.sax.InputSourceobjects as follows:org.xml.sax.InputSource xmlInputSource =new org.xml.sax.InputSource(xmlSystemId);org.xml.sax.InputSource xsltInputSource =new org.xml.sax.InputSource(xsltSystemId);This code is virtually indistinguishable from the Xalan code, except Xalan uses
XSLTInputSourceinstead ofInputSource. As mentioned before,XSLTInputSourceis merely a subclass ofInputSourcethat adds support for reading from a DOMNode. SAXON also has the ability to read from a DOM node, although its approach is slightly different.Creating a
Resultobject sets up the destination for the XSLT result tree, which is directed toSystem.outin this example:com.icl.saxon.trax.Result result =new com.icl.saxon.trax.Result(System.out);The XSLT stylesheet is then compiled, resulting in an object that can be used repeatedly from many concurrent threads:
com.icl.saxon.trax.Templates templates =processor.process(xsltInputSource);In a typical XML and XSLT web site, the XML data is generated dynamically, but the same stylesheets are used repeatedly. For instance, stylesheets generating common headers, footers, and navigation bars will be used by many pages. To maximize performance, you will want to process the stylesheets once and reuse the instances for many clients at the same time. For this reason, the thread safety that
Templatesoffers is critical.An instance of the
Transformerclass is then created to perform the actual transformation. Unlike the stylesheet itself, the transformer cannot be shared by many clients and is not thread-safe. If this was a servlet implementation, theTransformerinstance would have to be created with each invocation ofdoGetordoPost. In our example, the code is as follows:com.icl.saxon.trax.Transformer trans = templates.newTransformer( );trans.transform(xmlInputSource, result);SAXON, Xalan, or TrAX?
As the previous examples show, SAXON and Xalan have many similarities. While similarities make learning the various APIs easy, they do not result in portable code. If you write code directly against either of these interfaces, you lock yourself into that particular implementation unless you want to rewrite your application.
The other option is to write a facade around both processors, presenting a consistent interface that works with either processor behind the scenes. The only problem with this approach is that as new processors are introduced, you must update the implementation of your facade. It would be very difficult for one individual or organization to keep up with the rapidly changing world of XSLT processors.
But if the facade was an open standard and supported by a large enough user base, the people and organizations that write the XSLT processors would feel pressure to adhere to the common API, rather than the other way around. TrAX was initiated in early 2000 as an effort to define a consistent API to any XSLT processor. Since some of the key people behind TrAX were also responsible for implementing some of the major XSLT processors, it was quickly accepted that TrAX would be a de facto standard, much in the way that SAX is.
Introduction to JAXP 1.1
TrAX was a great idea, and the original work and concepts behind it were absorbed into JAXP Version 1.1. If you search for TrAX on the Web and get the feeling that the effort is waning, this is only because focus has shifted from TrAX to JAXP. Although the name has changed, the concept has not: JAXP provides a standard Java interface to many XSLT processors, allowing you to choose your favorite underlying implementation while retaining portability.
First released in March 2000, Sun's JAXP 1.0 utilized XML 1.0, XML Namespaces 1.0, SAX 1.0, and DOM Level 1. JAXP is a standard extension to Java, meaning that Sun provides a specification through its Java Community Process (JCP) as well as a reference implementation. JAXP 1.1 follows the same basic design philosophies of JAXP 1.0, adding support for DOM Level 2, SAX 2, and XSLT 1.0. A tool like JAXP is necessary because the XSLT specification defines only a transformation language; it says nothing about how to write a Java XSLT processor. Although they all perform the same basic tasks, every processor uses a different API and has its own set of programming conventions.
JAXP is not an XML parser, nor is it an XSLT processor. Instead, it provides a common Java interface that masks differences between various implementations of the supported standards. When using JAXP, your code can avoid dependencies on specific vendor tools, allowing flexibility to upgrade to newer tools when they become available.
The key to JAXP's design is the concept of plugability layers. These layers provide consistent Java interfaces to the underlying SAX, DOM, and XSLT implementations. In order to utilize one of these APIs, you must obtain a factory class without hardcoding Xalan or SAXON code into your application. This is accomplished via a lookup mechanism that relies on Java system properties. Since three separate plugability layers are used, you can use a DOM parser from one vendor, a SAX parser from another vendor, and yet another XSLT processor from someone else. In reality, you will probably need to use a DOM parser compatible with your XSLT processor if you try to transform the DOM tree directly. Figure 5-1 illustrates the high-level architecture of JAXP 1.1.
Figure 5-1. JAXP 1.1 architecture
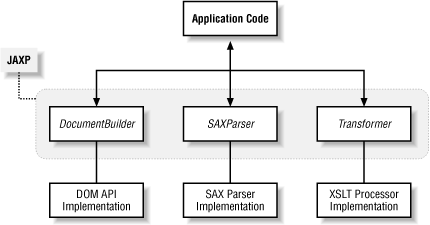
As shown, application code does not deal directly with specific parser or processor implementations, such as SAXON or Xalan. Instead, you write code against abstract classes that JAXP provides. This level of indirection allows you to pick and choose among different implementations without even recompiling your application.
The main drawback to an API such as JAXP is the "least common denominator" effect, which is all too familiar to AWT programmers. In order to maximize portability, JAXP mostly provides functionality that all XSLT processors support. This means, for instance, that Xalan's custom XPath APIs are not included in JAXP. In order to use value-added features of a particular processor, you must revert to nonportable code, negating the benefits of a plugability layer. Fortunately, most common tasks are supported by JAXP, so reverting to implementation-specific code is the exception, not the rule.
Although the JAXP specification does not define an XML parser or XSLT processor, reference implementations do include these tools. These reference implementations are open source Apache XML tools,[1] so complete source code is available.
JAXP 1.1 Implementation
You guessed it--we will now reimplement the simple example using Sun's JAXP 1.1. Behind the scenes, this could use any JAXP 1.1-compliant XSLT processor; this code was developed and tested using Apache's Xalan 2 processor. Example 5-3 contains the complete source code.
Example 5-3: SimpleJaxp.java
package chap5;import java.io.*;/*** A simple demo of JAXP 1.1*/public class SimpleJaxp {/*** Accept two command line arguments: the name of an XML file, and* the name of an XSLT stylesheet. The result of the transformation* is written to stdout.*/public static void main(String[] args)throws javax.xml.transform.TransformerException {if (args.length != 2) {System.err.println("Usage:");System.err.println(" java " + SimpleJaxp.class.getName( )+ " xmlFileName xsltFileName");System.exit(1);}File xmlFile = new File(args[0]);File xsltFile = new File(args[1]);javax.xml.transform.Source xmlSource =new javax.xml.transform.stream.StreamSource(xmlFile);javax.xml.transform.Source xsltSource =new javax.xml.transform.stream.StreamSource(xsltFile);javax.xml.transform.Result result =new javax.xml.transform.stream.StreamResult(System.out);// create an instance of TransformerFactoryjavax.xml.transform.TransformerFactory transFact =javax.xml.transform.TransformerFactory.newInstance( );javax.xml.transform.Transformer trans =transFact.newTransformer(xsltSource);trans.transform(xmlSource, result);}}As in the earlier examples, explicit package names are used in the code to point out which classes are parts of JAXP. In future examples,
importstatements will be favored because they result in less typing and more readable code. Our new program begins by declaring that it may throwTransformerException:public static void main(String[] args)throws javax.xml.transform.TransformerException {This is a general-purpose exception representing anything that might go wrong during the transformation process. In other processors, SAX-specific exceptions are typically propagated to the caller. In JAXP,
TransformerExceptioncan be wrapped around any type ofExceptionobject that various XSLT processors may throw.Next, the command-line arguments are converted into
Fileobjects. In the SAXON and Xalan examples, we created a system ID for each of these files. Since JAXP can read directly from aFileobject, the extra conversion to a URI is not needed:File xmlFile = new File(args[0]);File xsltFile = new File(args[1]);javax.xml.transform.Source xmlSource =new javax.xml.transform.stream.StreamSource(xmlFile);javax.xml.transform.Source xsltSource =new javax.xml.transform.stream.StreamSource(xsltFile);The
Sourceinterface is used to read both the XML file and the XSLT file. Unlike the SAXInputSourceclass or Xalan'sXSLTInputSourceclass,Sourceis an interface that can have many implementations. In this simple example we are usingStreamSource, which has the ability to read from aFileobject, anInputStream, aReader, or a system ID. Later we will examine additionalSourceimplementations that use SAX and DOM as input. Just likeSource,Resultis an interface that can have several implementations. In this example, aStreamResultsends the output of the transformations toSystem.out:javax.xml.transform.Result result =new javax.xml.transform.stream.StreamResult(System.out);Next, an instance of
TransformerFactoryis created:javax.xml.transform.TransformerFactory transFact =javax.xml.transform.TransformerFactory.newInstance( );The
TransformerFactoryis responsible for creatingTransformerandTemplateobjects. In our simple example, we create aTransformerobject:javax.xml.transform.Transformer trans =transFact.newTransformer(xsltSource);
Transformerobjects are not thread-safe, although they can be used multiple times. For a simple example like this, we will not encounter any problems. In a threaded servlet environment, however, multiple users cannot concurrently access the sameTransformerinstance. JAXP also provides aTemplatesinterface, which represents a stylesheet that can be accessed by many concurrent threads.The transformer instance is then used to perform the actual transformation:
trans.transform(xmlSource, result);This applies the XSLT stylesheet to the XML data, sending the result to
System.out.XSLT Plugability Layer
JAXP 1.1 defines a specific lookup procedure to locate an appropriate XSLT processor. This must be accomplished without hardcoding vendor-specific code into applications, so Java system properties and JAR file service providers are used. Within your code, first locate an instance of the
TransformerFactoryclass as follows:javax.xml.transform.TransformerFactory transFact =javax.xml.transform.TransformerFactory.newInstance( );Since
TransformerFactoryis abstract, itsnewInstance( )factory method is used to instantiate an instance of a specific subclass. The algorithm for locating this subclass begins by looking at thejavax.xml.transform.TransformerFactorysystem property. Let us suppose thatcom.foobar.AcmeTransformeris a new XSLT processor compliant with JAXP 1.1. To utilize this processor instead of JAXP's default processor, you can specify the system property on the command line[2] when you start your Java application:java -Djavax.xml.transform.TransformerFactory=com.foobar.AcmeTransformer MyAppProvided that JAXP is able to instantiate an instance of
AcmeTransformer, this is the XSLT processor that will be used. Of course,AcmeTransformermust be a subclass ofTransformerFactoryfor this to work, so it is up to vendors to offer support for JAXP.If the system property is not specified, JAXP next looks for a property file named lib/jaxp.properties in the JRE directory. A property file consists of
name=valuepairs, and JAXP looks for a line like this:javax.xml.transform.TransformerFactory=com.foobar.AcmeTransformerYou can obtain the location of the JRE with the following code:
String javaHomeDir = System.getProperty("java.home");TIP: Some popular development tools change the value of java.home when they are installed, which could prevent JAXP from locating jaxp.properties. JBuilder, for instance, installs its own version of Java 2 that it uses by default.
The advantage of creating jaxp.properties in this directory is that you can use your preferred processor for all of your applications that use JAXP without having to specify the system property on the command line. You can still override this file with the -D command-line syntax, however.
If jaxp.properties is not found, JAXP uses the JAR file service provider mechanism to locate an appropriate subclass of
TransformerFactory. The service provider mechanism is outlined in the JAR file specification from Sun and simply means that you must create a file in the META-INF/services directory of a JAR file. In JAXP, this file is called javax.xml.transform.TransformerFactory. It contains a single line that specifies the implementation ofTransformerFactory:com.foobar.AcmeTransformerin our fictitious example. If you look inside of xalan.jar in JAXP 1.1, you will find this file. In order to utilize a different parser that follows the JAXP 1.1 convention, simply make sure its JAR file is located first on your CLASSPATH.Finally, if JAXP cannot find an implementation class from any of the three locations, it uses its default implementation of
TransformerFactory. To summarize, here are the steps that JAXP performs when attempting to locate a factory:
- Use the value of the
javax.xml.transform.TransformerFactorysystem property if it exists.
- If JRE/lib/jaxp.properties exists, then look for a
javax.xml.transform.TransformerFactory=ImplementationClassentry in that file.
- Use a JAR file service provider to look for a file called META-INF/services/javax.xml.transform.TransformerFactory in any JAR file on the CLASSPATH.
- Use the default
TransformerFactoryinstance.
The JAXP 1.1 plugability layers for SAX and DOM follow the exact same process as the XSLT layer, only they use the
javax.xml.parsers.SAXParserFactoryandjavax.xml.parsers.DocumentBuilderFactorysystem properties respectively. It should be noted that JAXP 1.0 uses a much simpler algorithm where it checks only for the existence of the system property. If that property is not set, the default implementation is used.The Transformer Class
As shown in Example 5-3, a
Transformerobject can be obtained from theTransformerFactoryas follows:javax.xml.transform.TransformerFactory transFact =javax.xml.transform.TransformerFactory.newInstance( );javax.xml.transform.Transformer trans =transFact.newTransformer(xsltSource);The
Transformerinstance is wrapped around an XSLT stylesheet and allows you to perform as many transformations as you wish. The main caveat is thread safety, because many threads cannot use a singleTransformerinstance concurrently. For each transformation, invoke thetransformmethod:abstract void transform(Source xmlSource, Result outputTarget)throws TransformerExceptionThis method is abstract because the
TransformerFactoryreturns a subclass ofTransformerthat does the actual work. TheSourceinterface defines where the XML data comes from and theResultinterface specifies where the transformation result is sent. TheTransformerExceptionwill be thrown if anything goes wrong during the transformation process and may contain the location of the error and a reference to the original exception. The ability to properly report the location of the error is entirely dependent upon the quality of the underlying XSLT transformer implementation's error reporting. We will talk about specific classes that implement theSourceandResultinterfaces later in this chapter.Aside from actually performing the transformation, the
Transformerimplementation allows you to set output properties and stylesheet parameters. In XSLT, a stylesheet parameter is declared and used as follows:<?xml version="1.0" encoding="UTF-8"?><xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"><xsl:output method="html"/><xsl:param name="image_dir" select="'images'"/><xsl:template match="/"><html><body><h1>Stylesheet Parameter Example</h2><img src="{$image_dir}/sample.gif"/></body></html></xsl:template></xsl:stylesheet>The
<xsl:param>element declares the parameter name and an optionalselectattribute. This attribute specifies the default value if the stylesheet parameter is not provided. In this case, the string'images'is the default value and is enclosed in apostrophes so it is treated as a string instead of an XPath expression. Later, theimage_dirvariable is referred to with the attribute value template syntax:{$image_dir}.Passing a variable for the location of your images is a common technique because your development environment might use a different directory name than your production web server. Another common use for a stylesheet parameter is to pass in data that a servlet generates dynamically, such as a unique ID for session tracking.
From JAXP, pass this parameter via the
Transformerinstance. The code is simple enough:javax.xml.transform.Transformer trans =transFact.newTransformer(xsltSource);trans.setParameter("image_dir", "graphics");You can set as many parameters as you like, and these parameters will be saved and reused for every transformation you make with this
Transformerinstance. If you wish to remove a parameter, you must callclearParameters( ), which clears all parameters for thisTransformerinstance. Parameters work similarly to ajava.util.Map; if you set the same parameter twice, the second value overwrites the first value.Another use for the
Transformerclass is to get and set output properties through one of the following methods:void setOutputProperties(java.util.Properties props)void setOutputProperty(String name, String value)java.util.Properties getOutputProperties( )String getOutputProperty(String name)As you can see, properties are specified as name/value pairs of Strings and can be set and retrieved individually or as a group. Unlike stylesheet parameters, you can un-set an individual property by simply passing in
nullfor the value.The permitted property names are defined in thejavax.xml.transform.OutputKeysclass and are explained in Table 5-1.
Table 5-1: Constants defined in javax.xml.transform.OutputKeys Constant
Meaning
CDATA_SECTION_ELEMENTS
Specifies a whitespace-separated list of element names whose content should be output as CDATA sections. See the XSLT specification from the W3C for examples.
DOCTYPE_PUBLIC
Only used if
DOCTYPE_SYSTEMis also used, this instructs the processor to output a PUBLIC document type declaration. For example:<!DOCTYPE rootElem PUBLIC"public id" "system id">.DOCTYPE_SYSTEM
Instructs the processor to output a document-type declaration. For example:
<!DOCTYPE rootElem SYSTEM"system id">.ENCODING
Specifies the character encoding of the result tree, such as UTF-8 or UTF-16.
INDENT
Specifies whether or not whitespace may be added to the result tree, making the output more readable. Acceptable values are
yesandno. Although indentation makes the output more readable, it does make the file size larger, thus harming performance.MEDIA_TYPE
The MIME type of the result tree.
METHOD
The output method, either
xml,html, ortext. Although other values are possible, such asxhtml, these are implementation-defined and may be rejected by your processor.OMIT_XML_DECLARATION
Acceptable values are
yesandno, specifying whether or not to include the XML declaration on the first line of the result tree.STANDALONE
Acceptable values are
yesandno, specifying whether or not the XML declaration indicates that the document is standalone. For example:<?xml version="1.0"encoding="UTF-8" standalone="yes"?>.VERSION
Specifies the version of the output method, typically
1.0for XML output. This shows up in the XML declaration as follows:<?xml version="1.0" encoding="UTF-8"?>.It is no coincidence that these output properties are the same as the properties you can set on the
<xsl:output>element in your stylesheets. For example:<xsl:output method="xml" indent="yes" encoding="UTF-8"/>Using JAXP, you can either specify additional output properties or override those set in the stylesheet. To change the encoding, write this code:
// this will take precedence over any encoding specified in the stylesheettrans.setOutputProperty(OutputKeys.ENCODING, "UTF-16");Keep in mind that this will, in addition to adding
encoding="UTF-16"to the XML declaration, actually cause the processor to use that encoding in the result tree. For a value ofUTF-16, this means that 16-bit Unicode characters will be generated, so you may have trouble viewing the result tree in many ASCII-only text editors.JAXP XSLT Design
Now that we have seen some example code and have begun our exploration of the
Transformerclass, let's step back and look at the overall design of the XSLT plugability layer. JAXP support for XSLT is broken down into the packages listed in Table 5-2.
Table 5-2: JAXP transformation packages Package
Description
javax.xml.transform
Defines a general-purpose API for XML transformations without any dependencies on SAX or DOM. The
Transformerclass is obtained from theTransformerFactoryclass. TheTransformertransforms from aSourceto aResult.javax.xml.transform.dom
Defines how transformations can be performed using DOM. Provides implementations of
SourceandResult:DOMSourceandDOMResult.javax.xml.transform.sax
Supports SAX2 transformations. Defines SAX versions of
SourceandResult:SAXSourceandSAXResult. Also defines a subclass ofTransformerFactorythat allows SAX2 events to be fed into an XSLT processor.javax.xml.transform.stream
Defines I/O stream implementations of
SourceandResult:StreamSourceandStreamResult.The heart of JAXP XSLT support lies in the
javax.xml.transformpackage, which lays out the mechanics and overall process for any transformation that is performed. This package mostly consists of interfaces and abstract classes, except forOutputKeysand a few exception and error classes. Figure 5-2 presents a UML class diagram that shows all of the pieces in this important package.
Figure 5-2. javax.xml.transform class diagram
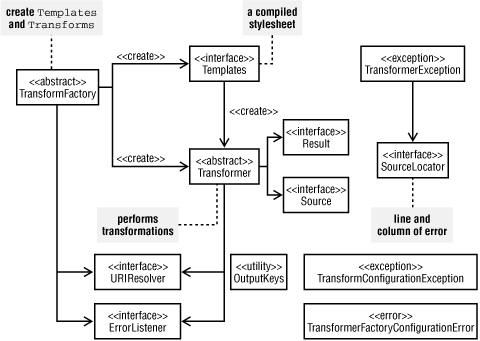
As you can see, this is a small package, indicative of the fact that JAXP is merely a wrapper around the tools that actually perform transformations. The entry point is
TransformerFactory, which creates instances ofTransformer, as we have already seen, as well as instances of theTemplatesabstract class. ATemplatesobject represents a compiled stylesheet and will be covered in detail later in this chapter.[3] The advantage of compilation is performance: the sameTemplatesobject can be used over and over by many threads without reparsing the XSLT file.The
URIResolveris responsible for resolving URIs found within stylesheets and is generally something you will not need to deal with directly. It is used when a stylesheet imports or includes another document, and the processor needs to figure out where to look for that document. For example:<xsl:import href="commonFooter.xslt"/>
ErrorListener, as you may guess, is an interface that allows your code to register as a listener for error conditions. This interface defines the following three methods:void error(TransformerException ex)void fatalError(TransformerException ex)void warning(TransformerException ex)The
TransformerExceptionhas the ability to wrap around anotherExceptionorThrowableobject and may return an instance of theSourceLocatorclass. If the underlying XSLT implementation does not provide aSourceLocator,nullis returned. TheSourceLocatorinterface defines methods to locate where aTransformerExceptionoriginated. In the case oferror()andwarning(), the XSLT processor is required to continue processing the document until the end. ForfatalError(), on the other hand, the XSLT processor is not required to continue. If you do not register anErrorListenerobject, then all errors, fatal errors, and warnings are normally written toSystem.err.TransformerFactoryConfigurationErrorandTransformerConfigurationExceptionround out the error-handling APIs for JAXP, indicating problems configuring the underlying XSLT processor implementation. TheTransformerFactoryConfigurationErrorclass is generally used when the implementation class cannot be found on the CLASSPATH or cannot be instantiated at all.TransformerConfigurationExceptionsimply indicates a "serious configuration error" according to its documentation.Input and Output
XSLT processors, like other XML tools, can read their input data from many different sources. In the most basic scenario, you will load a static stylesheet and XML document using the
java.io.Fileclass. More commonly, the XSLT stylesheet will come from a file, but the XML data will be generated dynamically as the result of a database query. In this case, it does not make sense to write the database query results to an XML file and then parse it into the XSLT processor. Instead, it is desirable to pipe the XML data directly into the processor using SAX or DOM. In fact, we will even see how to read nonXML data and transform it using XSLT.System Identifiers, Files, and URLs
The simple examples presented earlier in this chapter introduced the concept of a system identifier. As mentioned before, system identifiers are nothing more than URIs and are used frequently by XML tools. For example,
javax.xml.transform.Source,one of the key interfaces in JAXP, has the following API:public interface Source {String getSystemId( );void setSystemId(String systemId);}The second method,
setSystemId( ), is crucial. By providing a URI to theSource, the XSLT processor can resolve URIs encountered in XSLT stylesheets. This allows XSLT code like this to work:<xsl:import href="commonFooter.xslt"/>When it comes to XSLT programming, you will use methods in
java.io.Fileandjava.net.URLto convert platform-specific file names into system IDs. These can then be used as parameters to any methods that expect a system ID as a parameter. For example, you would write the following code to convert a platform-specific filename into a system ID:public static void main(String[] args) {// assume that the first command-line arg contains a file name// - on Windows, something like "C:\home\index.xml"// - on Unix, something like "/usr/home/index.xml"String fileName = args[0];File fileObject = new File(fileName);URL fileURL = fileObject.toURL( );String systemID = fileURL.toExternalForm( );This code was written on several lines for clarity; it can be consolidated as follows:
String systemID = new File(fileName).toURL().toExternalForm( );Converting from a system identifier back to a filename or a
Fileobject can be accomplished with this code:URL url = new URL(systemID);String fileName = url.getFile( );File fileObject = new File(fileName);And once again, this code can be condensed into a single line as follows:
File fileObject = new File((new URL(systemID)).getFile( ));JAXP I/O Design
The
SourceandResultinterfaces injavax.xml.transformprovide the basis for all transformation input and output in JAXP 1.1. Regardless of whether a stylesheet is obtained via a URI, filename, orInputStream, its data is fed into JAXP via an implementation of theSourceinterface. The output is then sent to an implementation of theResultinterface. The implementations provided by JAXP are shown in Figure 5-3.
Figure 5-3. Source and Result interfaces
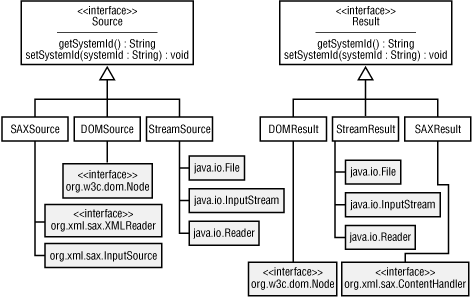
As you can see, JAXP is not particular about where it gets its data or sends its results. Remember that two instances of
Sourceare always specified: one for the XML data and another for the XSLT stylesheet.JAXP Stream I/O
As shown in Figure 5-3,
StreamSourceis one of the implementations of theSourceinterface. In addition to the system identifiers thatSourceprovides,StreamSourceallows input to be obtained from aFile, anInputStream, or aReader. TheSimpleJaxpclass in Example 5-3 showed how to useStreamSourceto read from aFileobject. There are also four constructors that allow you to construct aStreamSourcefrom either anInputStreamorReader. The complete list of constructors is shown here:public StreamSource( )public StreamSource(File f)public StreamSource(String systemId)public StreamSource(InputStream byteStream)public StreamSource(InputStream byteStream, String systemId)public StreamSource(Reader characterStream)public StreamSource(Reader characterStream, String systemId)For the constructors that take
InputStreamandReaderas arguments, the first argument provides either the XML data or the XSLT stylesheet. The second argument, if present, is used to resolve relative URI references in the document. As mentioned before, your XSLT stylesheet may include the following code:<xsl:import href="commonFooter.xslt"/>By providing a system identifier as a parameter to the
StreamSource, you are telling the XSLT processor where to look for commonFooter.xslt. Without this parameter, you may encounter an error when the processor cannot resolve this URI. The simple fix is to call thesetSystemId( )method as follows:// construct a Source that reads from an InputStreamSource mySrc = new StreamSource(anInputStream);// specify a system ID (a String) so the Source can resolve relative URLs// that are encountered in XSLT stylesheetsmySrc.setSystemId(aSystemId);The documentation for
StreamSourcealso advises thatInputStreamis preferred toReaderbecause this allows the processor to properly handle the character encoding as specified in the XML declaration.
StreamResultis similar in functionality toStreamSource, although it is not necessary to resolve relative URIs. The available constructors are as follows:public StreamResult( )public StreamResult(File f)public StreamResult(String systemId)public StreamResult(OutputStream byteStream)public StreamResult(Writer characterStream)Let's look at some of the other options for
StreamSourceandStreamResult. Example 5-4 is a modification of theSimpleJaxpprogram that was presented earlier. It downloads the XML specification from the W3C web site and stores it in a temporary file on your local disk. To download the file, construct aStreamSourcewith a system identifier as a parameter. The stylesheet is a simple one that merely performs an identity transformation, copying the unmodified XML data to the result tree. The result is then sent to aStreamResultusing itsFileconstructor.Example 5-4: Streams.java
package chap5;import java.io.*;import javax.xml.transform.*;import javax.xml.transform.stream.*;/*** A simple demo of JAXP 1.1 StreamSource and StreamResult. This* program downloads the XML specification from the W3C and prints* it to a temporary file.*/public class Streams {// an identity copy stylesheetprivate static final String IDENTITY_XSLT ="<xsl:stylesheet xmlns:xsl='http://www.w3.org/1999/XSL/Transform'"+ " version='1.0'>"+ "<xsl:template match='/'><xsl:copy-of select='.'/>"+ "</xsl:template></xsl:stylesheet>";// the XML spec in XML format// (using an HTTP URL rather than a file URL)private static String xmlSystemId ="http://www.w3.org/TR/2000/REC-xml-20001006.xml";public static void main(String[] args) throws IOException,TransformerException {// show how to read from a system identifier and a ReaderSource xmlSource = new StreamSource(xmlSystemId);Source xsltSource = new StreamSource(new StringReader(IDENTITY_XSLT));// send the result to a fileFile resultFile = File.createTempFile("Streams", ".xml");Result result = new StreamResult(resultFile);System.out.println("Results will go to: "+ resultFile.getAbsolutePath( ));// get the factoryTransformerFactory transFact = TransformerFactory.newInstance( );// get a transformer for this particular stylesheetTransformer trans = transFact.newTransformer(xsltSource);// do the transformationtrans.transform(xmlSource, result);}}The "identity copy" stylesheet simply matches
"/", which is the document itself. It then uses<xsl:copy-of select='.'/>to select the document and copy it to the result tree. In this case, we coded our own stylesheet. You can also omit the XSLT stylesheet altogether as follows:// construct a Transformer without any XSLT stylesheetTransformer trans = transFact.newTransformer( );In this case, the processor will provide its own stylesheet and do the same thing that our example does. This is useful when you need to use JAXP to convert a DOM tree to XML text for debugging purposes because the default
Transformerwill simply copy the XML data without any transformation.JAXP DOM I/O
In many cases, the fastest form of transformation available is to feed an instance of
org.w3c.dom.Documentdirectly into JAXP. Although the transformation is fast, it does take time to generate the DOM; DOM is also memory intensive, and may not be the best choice for large documents. In most cases, the DOM data will be generated dynamically as the result of a database query or some other operation (see Chapter 1). Once the DOM is generated, simply wrap theDocumentobject in aDOMSourceas follows:org.w3c.dom.Document domDoc = createDomDocument( );Source xmlSource = new javax.xml.transform.dom.DOMSource(domDoc);The remainder of the transformation looks identical to the file-based transformation shown in Example 5-4. JAXP needs only the alternate input
Sourceobject shown here to read from DOM.JAXP SAX I/O
XSLT is designed to transform well-formed XML data into another format, typically HTML. But wouldn't it be nice if we could also use XSLT stylesheets to transform nonXML data into HTML? For example, most spreadsheets have the ability to export their data into Comma Separated Values (CSV) format, as shown here:
Burke,Eric,MBurke,Jennifer,LBurke,Aidan,GOne approach is parsing the file into memory, using DOM to create an XML representation of the data, and then feeding that information into JAXP for transformation. This approach works but requires an intermediate programming step to convert the CSV file into a DOM tree. A better option is to write a custom SAX parser, feeding its output directly into JAXP. This avoids the overhead of constructing the DOM tree, offering better memory utilization and performance.
The approach
It turns out that writing a SAX parser is quite easy.[4] All a SAX parser does is read an XML file top to bottom and fire event notifications as various elements are encountered. In our custom parser, we will read the CSV file top to bottom, firing SAX events as we read the file. A program listening to those SAX events will not realize that the data file is CSV rather than XML; it sees only the events. Figure 5-4 illustrates the conceptual model.
Figure 5-4. Custom SAX parser

In this model, the XSLT processor interprets the SAX events as XML data and uses a normal stylesheet to perform the transformation. The interesting aspect of this model is that we can easily write custom SAX parsers for other file formats, making XSLT a useful transformation language for just about any legacy application data.
In SAX,
org.xml.sax.XMLReaderis a standard interface that parsers must implement. It works in conjunction withorg.xml.sax.ContentHandler, which is the interface that listens to SAX events. For this model to work, your XSLT processor must implement theContentHandlerinterface so it can listen to the SAX events that theXMLReadergenerates. In the case of JAXP,javax.xml.transform.sax.TransformerHandleris used for this purpose.Obtaining an instance of
TransformerHandlerrequires a few extra programming steps. First, create aTransformerFactoryas usual:TransformerFactory transFact = TransformerFactory.newInstance( );As before, the
TransformerFactoryis the JAXP abstraction to some underlying XSLT processor. This underlying processor may not support SAX features, so you have to query it to determine if you can proceed:if (transFact.getFeature(SAXTransformerFactory.FEATURE)) {If this returns
false, you are out of luck. Otherwise, you can safely downcast to aSAXTransformerFactoryand construct theTransformerHandlerinstance:SAXTransformerFactory saxTransFact =(SAXTransformerFactory) transFact;// create a ContentHandler, don't specify a stylesheet. Without// a stylesheet, raw XML is sent to the output.TransformerHandler transHand = saxTransFact.newTransformerHandler( );In the code shown here, a stylesheet was not specified. JAXP defaults to the identity transformation stylesheet, which means that the SAX events will be "transformed" into raw XML output. To specify a stylesheet that performs an actual transformation, pass a
Sourceto the method as follows:Source xsltSource = new StreamSource(myXsltSystemId);TransformerHandler transHand = saxTransFact.newTransformerHandler(xsltSource);Detailed CSV to SAX design
Before delving into the complete example program, let's step back and look at a more detailed design diagram. The conceptual model is straightforward, but quite a few classes and interfaces come into play. Figure 5-5 shows the pieces necessary for SAX-based transformations.
Figure 5-5. SAX and XSLT transformations
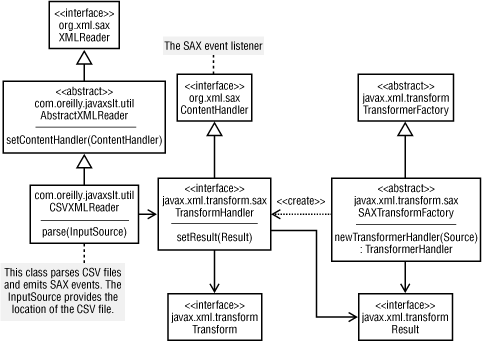
This diagram certainly appears to be more complex than previous approaches, but is similar in many ways. In previous approaches, we used the
TransformerFactoryto create instances ofTransformer; in the SAX approach, we start with a subclass ofTransformerFactory. Before any work can be done, you must verify that your particular implementation supports SAX-based transformations. The reference implementation of JAXP does support this, although other implementations are not required to do so. In the following code fragment, thegetFeaturemethod ofTransformerFactorywill returntrueif you can safely downcast to aSAXTransformerFactoryinstance:TransformerFactory transFact = TransformerFactory.newInstance( );if (transFact.getFeature(SAXTransformerFactory.FEATURE)) {// downcast is allowedSAXTransformerFactory saxTransFact = (SAXTransformerFactory) transFact;If
getFeaturereturnsfalse, your only option is to look for an implementation that does support SAX-based transformations. Otherwise, you can proceed to create an instance ofTransformerHandler:TransformerHandler transHand = saxTransFact.newTransformerHandler(myXsltSource);This object now represents your XSLT stylesheet. As Figure 5-5 shows,
TransformerHandlerextendsorg.xml.sax.ContentHandler, so it knows how to listen to events from a SAX parser. The series of SAX events will provide the "fake XML" data, so the only remaining piece of the puzzle is to set theResultand tell the SAX parser to begin parsing. TheTransformerHandleralso provides a reference to aTransformer, which allows you to set output properties such as the character encoding, whether to indent the output or any other attributes of<xsl:output>.Writing the custom parser
Writing the actual SAX parser sounds harder than it really is. The process basically involves implementing the
org.xml.sax.XMLReaderinterface, which provides numerous methods you can safely ignore for most applications. For example, when parsing a CSV file, it is probably not necessary to deal with namespaces or validation. The code forAbstractXMLReader.javais shown in Example 5-5. This is an abstract class that provides basic implementations of every method in theXMLReaderinterface except for theparse( )method. This means that all you need to do to write a parser is create a subclass and override this single method.Example 5-5: AbstractXMLReader.java
package com.oreilly.javaxslt.util;import java.io.IOException;import java.util.*;import org.xml.sax.*;/*** An abstract class that implements the SAX2 XMLReader interface. The* intent of this class is to make it easy for subclasses to act as* SAX2 XMLReader implementations. This makes it possible, for example, for* them to emit SAX2 events that can be fed into an XSLT processor for* transformation.*/public abstract class AbstractXMLReader implements org.xml.sax.XMLReader {private Map featureMap = new HashMap( );private Map propertyMap = new HashMap( );private EntityResolver entityResolver;private DTDHandler dtdHandler;private ContentHandler contentHandler;private ErrorHandler errorHandler;/*** The only abstract method in this class. Derived classes can parse* any source of data and emit SAX2 events to the ContentHandler.*/public abstract void parse(InputSource input) throws IOException,SAXException;public boolean getFeature(String name)throws SAXNotRecognizedException, SAXNotSupportedException {Boolean featureValue = (Boolean) this.featureMap.get(name);return (featureValue == null) ? false: featureValue.booleanValue( );}public void setFeature(String name, boolean value)throws SAXNotRecognizedException, SAXNotSupportedException {this.featureMap.put(name, new Boolean(value));}public Object getProperty(String name)throws SAXNotRecognizedException, SAXNotSupportedException {return this.propertyMap.get(name);}public void setProperty(String name, Object value)throws SAXNotRecognizedException, SAXNotSupportedException {this.propertyMap.put(name, value);}public void setEntityResolver(EntityResolver entityResolver) {this.entityResolver = entityResolver;}public EntityResolver getEntityResolver( ) {return this.entityResolver;}public void setDTDHandler(DTDHandler dtdHandler) {this.dtdHandler = dtdHandler;}public DTDHandler getDTDHandler( ) {return this.dtdHandler;}public void setContentHandler(ContentHandler contentHandler) {this.contentHandler = contentHandler;}public ContentHandler getContentHandler( ) {return this.contentHandler;}public void setErrorHandler(ErrorHandler errorHandler) {this.errorHandler = errorHandler;}public ErrorHandler getErrorHandler( ) {return this.errorHandler;}public void parse(String systemId) throws IOException, SAXException {parse(new InputSource(systemId));}}Creating the subclass,
CSVXMLReader, involves overriding theparse( )method and actually scanning through the CSV file, emitting SAX events as elements in the file are encountered. While the SAX portion is very easy, parsing the CSV file is a little more challenging. To make this class as flexible as possible, it was designed to parse through any CSV file that a spreadsheet such as Microsoft Excel can export. For simple data, your CSV file might look like this:Burke,Eric,MBurke,Jennifer,LBurke,Aidan,GThe XML representation of this file is shown in Example 5-6. The only real drawback here is that CSV files are strictly positional, meaning that names are not assigned to each column of data. This means that the XML output merely contains a sequence of three
<value>elements for each line, so your stylesheet will have to select items based on position.Example 5-6: Example XML output from CSV parser
<?xml version="1.0" encoding="UTF-8"?><csvFile><line><value>Burke</value><value>Eric</value><value>M</value></line><line><value>Burke</value><value>Jennifer</value><value>L</value></line><line><value>Burke</value><value>Aidan</value><value>G</value></line></csvFile>One enhancement would be to design the CSV parser so it could accept a list of meaningful column names as parameters, and these could be used in the XML that is generated. Another option would be to write an XSLT stylesheet that transformed this initial output into another form of XML that used meaningful column names. To keep the code example relatively manageable, these features were omitted from this implementation. But there are some complexities to the CSV file format that have to be considered. For example, fields that contain commas must be surrounded with quotes:
"Consultant,Author,Teacher",Burke,Eric,MTeacher,Burke,Jennifer,LNone,Burke,Aidan,GTo further complicate matters, fields may also contain quotes ("). In this case, they are doubled up, much in the same way you use double backslash characters (\\) in Java to represent a single backslash. In the following example, the first column contains a single quote, so the entire field is quoted, and the single quote is doubled up:
"test""quote",Teacher,Burke,Jennifer,LThis would be interpreted as:
test"quote,Teacher,Burke,Jennifer,LThe code in Example 5-7 shows the complete implementation of the CSV parser.
Example 5-7: CSVXMLReader.java
package com.oreilly.javaxslt.util;import java.io.*;import java.net.URL;import org.xml.sax.*;import org.xml.sax.helpers.*;/*** A utility class that parses a Comma Separated Values (CSV) file* and outputs its contents using SAX2 events. The format of CSV that* this class reads is identical to the export format for Microsoft* Excel. For simple values, the CSV file may look like this:* <pre>* a,b,c* d,e,f* </pre>* Quotes are used as delimiters when the values contain commas:* <pre>* a,"b,c",d* e,"f,g","h,i"* </pre>* And double quotes are used when the values contain quotes. This parser* is smart enough to trim spaces around commas, as well.** @author Eric M. Burke*/public class CSVXMLReader extends AbstractXMLReader {// an empty attribute for use with SAXprivate static final Attributes EMPTY_ATTR = new AttributesImpl( );/*** Parse a CSV file. SAX events are delivered to the ContentHandler* that was registered via <code>setContentHandler</code>.** @param input the comma separated values file to parse.*/public void parse(InputSource input) throws IOException,SAXException {// if no handler is registered to receive events, don't bother// to parse the CSV fileContentHandler ch = getContentHandler( );if (ch == null) {return;}// convert the InputSource into a BufferedReaderBufferedReader br = null;if (input.getCharacterStream( ) != null) {br = new BufferedReader(input.getCharacterStream( ));} else if (input.getByteStream( ) != null) {br = new BufferedReader(new InputStreamReader(input.getByteStream( )));} else if (input.getSystemId( ) != null) {java.net.URL url = new URL(input.getSystemId( ));br = new BufferedReader(new InputStreamReader(url.openStream( )));} else {throw new SAXException("Invalid InputSource object");}ch.startDocument( );// emit <csvFile>ch.startElement("","","csvFile",EMPTY_ATTR);// read each line of the file until EOF is reachedString curLine = null;while ((curLine = br.readLine( )) != null) {curLine = curLine.trim( );if (curLine.length( ) > 0) {// create the <line> elementch.startElement("","","line",EMPTY_ATTR);// output data from this lineparseLine(curLine, ch);// close the </line> elementch.endElement("","","line");}}// emit </csvFile>ch.endElement("","","csvFile");ch.endDocument( );}// Break an individual line into tokens. This is a recursive function// that extracts the first token, then recursively parses the// remainder of the line.private void parseLine(String curLine, ContentHandler ch)throws IOException, SAXException {String firstToken = null;String remainderOfLine = null;int commaIndex = locateFirstDelimiter(curLine);if (commaIndex > -1) {firstToken = curLine.substring(0, commaIndex).trim( );remainderOfLine = curLine.substring(commaIndex+1).trim( );} else {// no commas, so the entire line is the tokenfirstToken = curLine;}// remove redundant quotesfirstToken = cleanupQuotes(firstToken);// emit the <value> elementch.startElement("","","value",EMPTY_ATTR);ch.characters(firstToken.toCharArray(), 0, firstToken.length( ));ch.endElement("","","value");// recursively process the remainder of the lineif (remainderOfLine != null) {parseLine(remainderOfLine, ch);}}// locate the position of the comma, taking into account that// a quoted token may contain ignorable commas.private int locateFirstDelimiter(String curLine) {if (curLine.startsWith("\"")) {boolean inQuote = true;int numChars = curLine.length( );for (int i=1; i<numChars; i++) {char curChar = curLine.charAt(i);if (curChar == '"') {inQuote = !inQuote;} else if (curChar == ',' && !inQuote) {return i;}}return -1;} else {return curLine.indexOf(',');}}// remove quotes around a token, as well as pairs of quotes// within a token.private String cleanupQuotes(String token) {StringBuffer buf = new StringBuffer( );int length = token.length( );int curIndex = 0;if (token.startsWith("\"") && token.endsWith("\"")) {curIndex = 1;length--;}boolean oneQuoteFound = false;boolean twoQuotesFound = false;while (curIndex < length) {char curChar = token.charAt(curIndex);if (curChar == '"') {twoQuotesFound = (oneQuoteFound) ? true : false;oneQuoteFound = true;} else {oneQuoteFound = false;twoQuotesFound = false;}if (twoQuotesFound) {twoQuotesFound = false;oneQuoteFound = false;curIndex++;continue;}buf.append(curChar);curIndex++;}return buf.toString( );}}
CSVXMLReaderis a subclass ofAbstractXMLReader, so it must provide an implementation of the abstractparsemethod:public void parse(InputSource input) throws IOException,SAXException {// if no handler is registered to receive events, don't bother// to parse the CSV fileContentHandler ch = getContentHandler( );if (ch == null) {return;}The first thing this method does is check for the existence of a SAX
ContentHandler. The base class,AbstractXMLReader, provides access to this object, which is responsible for listening to the SAX events. In our example, an instance of JAXP'sTransformerHandleris used as the SAXContentHandlerimplementation. If this handler is not registered, ourparsemethod simply returns because nobody is registered to listen to the events. In a real SAX parser, the XML would be parsed anyway, which provides an opportunity to check for errors in the XML data. Choosing to return immediately was merely a performance optimization selected for this class.The SAX
InputSourceparameter allows our custom parser to locate the CSV file. Since anInputSourcehas many options for reading its data, parsers must check each potential source in the order shown here:// convert the InputSource into a BufferedReaderBufferedReader br = null;if (input.getCharacterStream( ) != null) {br = new BufferedReader(input.getCharacterStream( ));} else if (input.getByteStream( ) != null) {br = new BufferedReader(new InputStreamReader(input.getByteStream( )));} else if (input.getSystemId( ) != null) {java.net.URL url = new URL(input.getSystemId( ));br = new BufferedReader(new InputStreamReader(url.openStream( )));} else {throw new SAXException("Invalid InputSource object");}Assuming that our
InputSourcewas valid, we can now begin parsing the CSV file and emitting SAX events. The first step is to notify theContentHandlerthat a new document has begun:ch.startDocument( );// emit <csvFile>ch.startElement("","","csvFile",EMPTY_ATTR);The XSLT processor interprets this to mean the following:
<?xml version="1.0" encoding="UTF-8"?><csvFile>Our parser simply ignores many SAX 2 features, particularly XML namespaces. This is why many values passed as parameters to the various
ContentHandlermethods simply contain empty strings. TheEMPTY_ATTRconstant indicates that this XML element does not have any attributes.The CSV file itself is very straightforward, so we merely loop over every line in the file, emitting SAX events as we read each line. The
parseLinemethod is a private helper method that does the actual CSV parsing:// read each line of the file until EOF is reachedString curLine = null;while ((curLine = br.readLine( )) != null) {curLine = curLine.trim( );if (curLine.length( ) > 0) {// create the <line> elementch.startElement("","","line",EMPTY_ATTR);parseLine(curLine, ch);ch.endElement("","","line");}}And finally, we must indicate that the parsing is complete:
// emit </csvFile>ch.endElement("","","csvFile");ch.endDocument( );The remaining methods in
CSVXMLReaderare not discussed in detail here because they are really just responsible for breaking down each line in the CSV file and checking for commas, quotes, and other mundane parsing tasks. One thing worth noting is the code that emits text, such as the following:<value>Some Text Here</value>SAX parsers use the
charactersmethod onContentHandlerto represent text, which has this signature:public void characters(char[] ch, int start, int length)Although this method could have been designed to take a
String, using an array allows SAX parsers to preallocate a large character array and then reuse that buffer repeatedly. This is why an implementation ofContentHandlercannot simply assume that the entirecharray contains meaningful data. Instead, it must read only the specified number of characters beginning at thestartposition.Our parser uses a relatively straightforward approach, simply converting a
Stringto a character array and passing that as a parameter to thecharactersmethod:// emit the <value>text</value> elementch.startElement("","","value",EMPTY_ATTR);ch.characters(firstToken.toCharArray(), 0, firstToken.length( ));ch.endElement("","","value");Using the parser
To wrap things up, let's look at how you will actually use this CSV parser with an XSLT stylesheet. The code shown in Example 5-8 is a standalone Java application that allows you to perform XSLT transformations on CSV files. As the comments indicate, it requires the name of a CSV file as its first parameter and can optionally take the name of an XSLT stylesheet as its second parameter. All output is sent to
System.out.Example 5-8: SimpleCSVProcessor.java
package com.oreilly.javaxslt.util;import java.io.*;import javax.xml.transform.*;import javax.xml.transform.sax.*;import javax.xml.transform.stream.*;import org.xml.sax.*;/*** Shows how to use the CSVXMLReader class. This is a command-line* utility that takes a CSV file and optionally an XSLT file as* command line parameters. A transformation is applied and the* output is sent to System.out.*/public class SimpleCSVProcessor {public static void main(String[] args) throws Exception {if (args.length == 0) {System.err.println("Usage: java "+ SimpleCSVProcessor.class.getName( )+ " <csvFile> [xsltFile]");System.err.println(" - csvFile is required");System.err.println(" - xsltFile is optional");System.exit(1);}String csvFileName = args[0];String xsltFileName = (args.length > 1) ? args[1] : null;TransformerFactory transFact = TransformerFactory.newInstance( );if (transFact.getFeature(SAXTransformerFactory.FEATURE)) {SAXTransformerFactory saxTransFact =(SAXTransformerFactory) transFact;TransformerHandler transHand = null;if (xsltFileName == null) {transHand = saxTransFact.newTransformerHandler( );} else {transHand = saxTransFact.newTransformerHandler(new StreamSource(new File(xsltFileName)));}// set the destination for the XSLT transformationtransHand.setResult(new StreamResult(System.out));// hook the CSVXMLReader to the CSV fileCSVXMLReader csvReader = new CSVXMLReader( );InputSource csvInputSrc = new InputSource(new FileReader(csvFileName));// attach the XSLT processor to the CSVXMLReadercsvReader.setContentHandler(transHand);csvReader.parse(csvInputSrc);} else {System.err.println("SAXTransformerFactory is not supported.");System.exit(1);}}}As mentioned earlier in this chapter, the
TransformerHandleris provided by JAXP and is an implementation of theorg.xml.sax.ContentHandlerinterface. It is constructed by theSAXTransformerFactoryas follows:TransformerHandler transHand = null;if (xsltFileName == null) {transHand = saxTransFact.newTransformerHandler( );} else {transHand = saxTransFact.newTransformerHandler(new StreamSource(new File(xsltFileName)));}When the XSLT stylesheet is not specified, the transformer performs an identity transformation. This is useful when you just want to see the raw XML output without applying a stylesheet. You will probably want to do this first to see how your XSLT will need to be written. If a stylesheet is provided, however, it is used for the transformation.
The custom parser is then constructed as follows:
CSVXMLReader csvReader = new CSVXMLReader( );The location of the CSV file is then converted into a SAX
InputSource:InputSource csvInputSrc = new InputSource(new FileReader(csvFileName));And finally, the XSLT processor is attached to our custom parser. This is accomplished by registering the
TransformerHandleras theContentHandleroncsvReader. A single call to theparsemethod causes the parsing and transformation to occur:// attach the XSLT processor to the CSVXMLReadercsvReader.setContentHandler(transHand);csvReader.parse(csvInputSrc);For a simple test, assume that a list of presidents is available in CSV format:
Washington,George,,Adams,John,,Jefferson,Thomas,,Madison,James,,etc...Bush,George,Herbert,WalkerClinton,William,Jefferson,Bush,George,W,To see what the XML looks like, invoke the program as follows:
java com.oreilly.javaxslt.util.SimpleCSVProcessor presidents.csvThis will parse the CSV file and apply the identity transformation stylesheet, sending the following output to the console:
<?xml version="1.0" encoding="UTF-8"?><csvFile><line><value>Washington</value><value>George</value><value/><value/></line><line>etc...</csvFile>Actually, the output is crammed onto a single long line, but it is broken up here to make it more readable. Any good XML editor application should provide a feature to pretty-print the XML as shown. In order to transform this into something useful, a stylesheet is required. The XSLT stylesheet shown in Example 5-9 takes any output from this program and converts it into an HTML table.
Example 5-9: csvToHTMLTable.xslt
<?xml version="1.0" encoding="UTF-8"?><xsl:stylesheetversion="1.0"xmlns:xsl="http://www.w3.org/1999/XSL/Transform"><xsl:output method="html"/><xsl:template match="/"><table border="1"><xsl:apply-templates select="csvFile/line"/></table></xsl:template><xsl:template match="line"><tr><xsl:apply-templates select="value"/></tr></xsl:template><xsl:template match="value"><td><!-- If a value is empty, print a non-breaking spaceso the HTML table looks OK --><xsl:if test=".=''"><xsl:text> disable-output-escaping="yes">&nbsp;</xsl:text></xsl:if><xsl:value-of select="."/></td></xsl:template></xsl:stylesheet>In order to apply this stylesheet, type the following command:
java com.oreilly.javaxslt.util.SimpleCSVProcessor presidents.csv csvToHTMLTable.xsltAs before, the results are sent to
System.outand contain code for an HTML table. This stylesheet will work with any CSV file parsed withSimpleCSVProcessor, not just presidents.xml. Now that the concept has been proved, you can add fancy formatting and custom output to the resulting HTML without altering any Java code--just edit the stylesheet or write a new one.Conclusion
Although writing a SAX parser and connecting it to JAXP does involve quite a few interrelated classes, the resulting application requires only two command-line arguments and will work with any CSV or XSLT file. What makes this example interesting is that the same approach will work with essentially any data source. The steps are broken down as follows:
- Create a custom SAX parser by implementing
org.xml.sax.XMLReaderor extendingcom.oreilly.javaxslt.util.AbstractXMLReader.
- In your parser, emit the appropriate SAX events as you read your data.
- Modify
SimpleCSVProcessorto utilize your custom parser instead ofCSVXMLReader.
For example, you might want to write a custom parser that accepts a SQL statement as input rather than a CSV file. Your parser could then connect to a database, issue the query, and fire SAX events for each row in the
ResultSet. This makes it very easy to extract data from any relational database without writing a lot of custom code. This also eliminates the intermediate step of JDOM or DOM production because the SAX events are fed directly into JAXP for transformation.Feeding JDOM Output into JAXP
The DOM API is tedious to use, so many Java programmers opt for JDOM instead. The typical usage pattern is to generate XML dynamically using JDOM and then somehow transform that into a web page using XSLT. This presents a problem because JAXP does not provide any direct implementation of the
javax.xml.Sourceinterface that integrates with JDOM.[5] There are at least three available options:
- Use
org.jdom.output.SAXOutputtertopipe SAX 2 events from JDOM to JAXP.
- Use
org.jdom.output.DOMOutputtertoconvert the JDOM tree to a DOM tree, and then usejavax.xml.transform.dom.DOMSourceto read the data into JAXP.
- Use
org.jdom.output.XMLOutputtertoserialize the JDOM tree to XML text, and then usejava.xml.transform.stream.StreamSourceto parse the XML back into JAXP.
JDOM to SAX approach
The SAX approach is generally preferable to other approaches. Its primary advantage is that it does not require an intermediate transformation to convert the JDOM tree into a DOM tree or text. This offers the lowest memory utilization and potentially the fastest performance.
In support of SAX, JDOM offers the
org.jdom.output.SAXOutputterclass. The following code fragment demonstrates its usage:TransformerFactory transFact = TransformerFactory.newInstance( );if (transFact.getFeature(SAXTransformerFactory.FEATURE)) {SAXTransformerFactory stf = (SAXTransformerFactory) transFact;// the 'stylesheet' parameter is an instance of JAXP's// javax.xml.transform.Templates interfaceTransformerHandler transHand = stf.newTransformerHandler(stylesheet);// result is a Result instancetransHand.setResult(result);SAXOutputter saxOut = new SAXOutputter(transHand);// the 'jdomDoc' parameter is an instance of JDOM's// org.jdom.Document class. In contains the XML datasaxOut.output(jdomDoc);} else {System.err.println("SAXTransformerFactory is not supported");}JDOM to DOM approach
The DOM approach is generally a little slower and will not work if JDOM uses a different DOM implementation than JAXP. JDOM, like JAXP, can utilize different DOM implementations behind the scenes. If JDOM refers to a different version of DOM than JAXP, you will encounter exceptions when you try to perform the transformation. Since JAXP uses Apache's Crimson parser by default, you can configure JDOM to use Crimson with the
org.jdom.adapters.CrimsonDOMAdapterclass. The following code shows how to convert a JDOM Document into a DOM Document:org.jdom.Document jdomDoc = createJDOMDocument( );// add data to the JDOM Document...// convert the JDOM Document into a DOM Documentorg.jdom.output.DOMOutputter domOut = new org.jdom.output.DOMOutputter("org.jdom.adapters.CrimsonDOMAdapter");org.w3c.dom.Document domDoc = domOut.output(jdomDoc);The second line is highlighted because it is likely to give you the most problems. When JDOM converts its internal object tree into a DOM object tree, it must use some underlying DOM implementation. In many respects, JDOM is similar to JAXP because it delegates many tasks to underlying implementation classes. The
DOMOutputterconstructors are overloaded as follows:// use the default adapter classpublic DOMOutputter( )// use the specified adapter classpublic DOMOutputter(String adapterClass)The first constructor shown here will use JDOM's default DOM parser, which is not necessarily the same DOM parser that JAXP uses. The second method allows you to specify the name of an adapter class, which must implement the
org.jdom.adapters.DOMAdapterinterface. JDOM includes standard adapters for all of the widely used DOM implementations, or you could write your own adapter class.JDOM to text approach
In the final approach listed earlier, you can utilize
java.io.StringWriterandjava.io.StringReader. First create the JDOM data as usual, then useorg.jdom.output.XMLOutputtertoconvert the data into aStringof XML:StringWriter sw = new StringWriter( );org.jdom.output.XMLOutputter xmlOut= new org.jdom.output.XMLOutputter("", false);xmlOut.output(jdomDoc, sw);The parameters for
XMLOutputterallow you to specify the amount of indentation for the output along with abooleanflag indicating whether or not linefeeds should be included in the output. In the code example, no spaces or linefeeds are specified in order to minimize the size of the XML that is produced. Now that theStringWritercontains your XML, you can use aStringReaderalong withjavax.xml.transform.stream.StreamSourceto read the data into JAXP:StringReader sr = new StringReader(sw.toString( ));Source xmlSource = new javax.xml.transform.stream.StreamSource(sr);The transformation can then proceed just as it did in Example 5-4. The main drawback to this approach is that the XML, once converted to text form, must then be parsed back in by JAXP before the transformation can be applied.
Stylesheet Compilation
XSLT is a programming language, expressed using XML syntax. This is not for the benefit of the computer, but rather for human interpretation. Before the stylesheet can be processed, it must be converted into some internal machine-readable format. This process should sound familiar, because it is the same process used for every high-level programming language. You, the programmer, work in terms of the high-level language, and an interpreter or compiler converts this language into some machine format that can be executed by the computer.
Interpreters analyze source code and translate it into machine code with each execution. In this case of XSLT, this requires that the stylesheet be read into memory using an XML parser, translated into machine format, and then applied to your XML data. Performance is the obvious problem, particularly when you consider that stylesheets rarely change. Typically, the stylesheets are defined early on in the development process and remain static, while XML data is generated dynamically with each client request.
A better approach is to parse the XSLT stylesheet into memory once, compile it to machine-format, and then preserve that machine representation in memory for repeated use. This is called stylesheet compilation and is no different in concept than the compilation of any programming language.
Templates API
Different XSLT processors implement stylesheet compilation differently, so JAXP includes the
javax.xml.transform.Templatesinterface to provide consistency. This is a relatively simple interface with the following API:public interface Templates {java.util.Properties getOutputProperties( );javax.xml.transform.Transformer newTransformer( )throws TransformerConfigurationException;}The
getOutputProperties( )method returns a clone of the properties associated with the<xsl:output>element, such asmethod="xml",indent="yes", andencoding="UTF-8". You might recall thatjava.util.Properties(a subclass ofjava.util.Hashtable) provides key/value mappings from property names to property values. Since a clone, or deep copy, is returned, you can safely modify thePropertiesinstance and apply it to a future transformation without affecting the compiled stylesheet that the instance ofTemplatesrepresents.The
newTransformer( )method is more commonly used and allows you to obtain a new instance of a class that implements theTransformerinterface. It is thisTransformerobject that actually allows you to perform XSLT transformations. Since the implementation of theTemplatesinterface is hidden by JAXP, it must be created by the following method onjavax.xml.transform.TransformerFactory:public Templates newTemplates(Source source)throws TransformerConfigurationExceptionAs in earlier examples, the
Sourcemay obtain the XSLT stylesheet from one of many locations, including a filename, a system identifier, or even a DOM tree. Regardless of the original location, the XSLT processor is supposed to compile the stylesheet into an optimized internal representation.Whether the stylesheet is actually compiled is up to the implementation, but a safe bet is that performance will continually improve over the next several years as these tools stabilize and vendors have time to apply optimizations.
Figure 5-6 illustrates the relationship between
TemplatesandTransformerinstances.
Figure 5-6. Relationship between Templates and Transformer
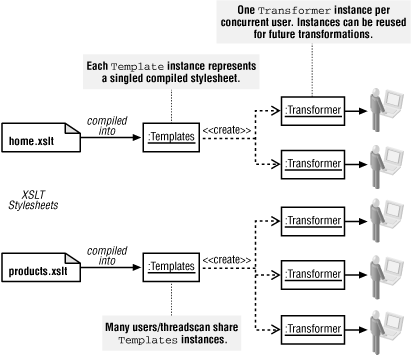
Thread safety is an important issue in any Java application, particularly in a web context where many users share the same stylesheet. As Figure 5-6 illustrates, an instance of
Templatesis thread-safe and represents a single stylesheet. During the transformation process, however, the XSLT processor must maintain state information and output properties specific to the current client. For this reason, a separateTransformerinstance must be used for each concurrent transformation.
Transformeris an abstract class in JAXP, and implementations should be lightweight. This is an important goal because you will typically create many copies ofTransformer, while the number ofTemplatesis relatively small.Transformerinstances are not thread-safe, primarily because they hold state information about the current transformation. Once the transformation is complete, however, these objects can be reused.A Stylesheet Cache
XSLT transformations commonly occur on a shared web server with a large number of concurrent users, so it makes sense to use
Templateswhenever possible to optimize performance. Since each instance ofTemplatesis thread-safe, it is desirable to maintain a single copy shared by many clients. This reduces the number of times your stylesheets have to be parsed into memory and compiled, as well as the overall memory footprint of your application.The code shown in Example 5-10 illustrates a custom XSLT stylesheet cache that automates the mundane tasks associated with creating
Templatesinstances and storing them in memory. This cache has the added benefit of checking thelastModifiedflag on the underlying file, so it will reload itself whenever the XSLT stylesheet is modified. This is highly useful in a web-application development environment because you can make changes to the stylesheet and simply click on Reload on your web browser to see the results of the latest edits.Example 5-10: StylesheetCache.java
package com.oreilly.javaxslt.util;import java.io.*;import java.util.*;import javax.xml.transform.*;import javax.xml.transform.stream.*;/*** A utility class that caches XSLT stylesheets in memory.**/public class StylesheetCache {// map xslt file names to MapEntry instances// (MapEntry is defined below)private static Map cache = new HashMap( );/*** Flush all cached stylesheets from memory, emptying the cache.*/public static synchronized void flushAll( ) {cache.clear( );}/*** Flush a specific cached stylesheet from memory.** @param xsltFileName the file name of the stylesheet to remove.*/public static synchronized void flush(String xsltFileName) {cache.remove(xsltFileName);}/*** Obtain a new Transformer instance for the specified XSLT file name.* A new entry will be added to the cache if this is the first request* for the specified file name.** @param xsltFileName the file name of an XSLT stylesheet.* @return a transformation context for the given stylesheet.*/public static synchronized Transformer newTransformer(String xsltFileName)throws TransformerConfigurationException {File xsltFile = new File(xsltFileName);ermine when the file was last modified on disklong xslLastModified = xsltFile.lastModified( );MapEntry entry = (MapEntry) cache.get(xsltFileName);if (entry != null) {// if the file has been modified more recently than the// cached stylesheet, remove the entry referenceif (xslLastModified > entry.lastModified) {entry = null;}}// create a new entry in the cache if necessaryif (entry == null) {Source xslSource = new StreamSource(xsltFile);TransformerFactory transFact = TransformerFactory.newInstance( );Templates templates = transFact.newTemplates(xslSource);entry = new MapEntry(xslLastModified, templates);cache.put(xsltFileName, entry);}return entry.templates.newTransformer( );}// prevent instantiation of this classprivate StylesheetCache( ) {}/*** This class represents a value in the cache Map.*/static class MapEntry {long lastModified; // when the file was modifiedTemplates templates;MapEntry(long lastModified, Templates templates) {this.lastModified = lastModified;this.templates = templates;}}}Because this class is a singleton, it has a private constructor and uses only static methods. Furthermore, each method is declared as
synchronizedin an effort to avoid potential threading problems.The heart of this class is the cache itself, which is implemented using
java.util.Map:private static Map cache = new HashMap( );Although
HashMapis not thread-safe, the fact that all of our methods aresynchronizedbasically eliminates any concurrency issues. Each entry in the map contains a key/value pair, mapping from an XSLT stylesheet filename to an instance of theMapEntryclass.MapEntryis a nested class that keeps track of the compiled stylesheet along with when its file was last modified:static class MapEntry {long lastModified; // when the file was modifiedTemplates templates;MapEntry(long lastModified, Templates templates) {this.lastModified = lastModified;this.templates = templates;}}Removing entries from the cache is accomplished by one of two methods:
public static synchronized void flushAll( ) {cache.clear( );}public static synchronized void flush(String xsltFileName) {cache.remove(xsltFileName);}The first method merely removes everything from the
Map, while the second removes a single stylesheet. Whether you use these methods is up to you. TheflushAllmethod, for instance, should probably be called from a servlet'sdestroy( )method to ensure proper cleanup. If you have many servlets in a web application, each servlet may wish to flush specific stylesheets it uses via theflush(...)method. If thexsltFileNameparameter is not found, theMapimplementation silently ignores this request.The majority of interaction with this class occurs via the
newTransformermethod, which has the following signature:public static synchronized Transformer newTransformer(String xsltFileName)throws TransformerConfigurationException {The parameter, an XSLT stylesheet filename, was chosen to facilitate the "last accessed" feature. We use the
java.io.Fileclass to determine when the file was last modified, which allows the cache to automatically reload itself as edits are made to the stylesheets. Had we used a system identifier orInputStreaminstead of a filename, the auto-reload feature could not have been implemented. Next, theFileobject is created and itslastModifiedflag is checked:File xsltFile = new File(xsltFileName);// determine when the file was last modified on disklong xslLastModified = xsltFile.lastModified( );The compiled stylesheet, represented by an instance of
MapEntry, is then retrieved from theMap. If the entry is found, its timestamp is compared against the current file's timestamp, thus allowing auto-reload:MapEntry entry = (MapEntry) cache.get(xsltFileName);if (entry != null) {// if the file has been modified more recently than the// cached stylesheet, remove the entry referenceif (xslLastModified > entry.lastModified) {entry = null;}}Next, we create a new entry in the cache if the entry object reference is still
null. This is accomplished by wrapping aStreamSourcearound theFileobject, instantiating aTransformerFactoryinstance, and using that factory to create ourTemplatesobject. TheTemplatesobject is then stored in the cache so it can be reused by the next client of the cache:// create a new entry in the cache if necessaryif (entry == null) {Source xslSource = new StreamSource(xsltFile);TransformerFactory transFact = TransformerFactory.newInstance( );Templates templates = transFact.newTemplates(xslSource);entry = new MapEntry(xslLastModified, templates);cache.put(xsltFileName, entry);}Finally, a brand new
Transformeris created and returned to the caller:return entry.templates.newTransformer( );Returning a new
Transformeris critical because, although theTemplatesobject is thread-safe, theTransformerimplementation is not. Each caller gets its own copy ofTransformerso multiple clients do not collide with one another.One potential improvement on this design could be to add a
lastAccessedtimestamp to eachMapEntryobject. Another thread could then execute every couple of hours to flush map entries from memory if they have not been accessed for a period of time. In most web applications, this will not be an issue, but if you have a large number of pages and some are seldom accessed, this could be a way to reduce the memory usage of the cache.Another potential modification is to allow
javax.xml.transform.Sourceobjects to be passed as a parameter to thenewTransformermethod instead of as a filename. However, this would make the auto-reload feature impossible to implement for allSourcetypes.
2. System properties can also be specified in Ant build files.
3. The exact definition of a "compiled" stylesheet is vague. XSLT processors are free to optimize cached stylesheets however they see fit.
5. As this is being written, members of the JDOM community are writing a JDOM implementation of
javax.xml.Sourcethat will directly integrate with JAXP.
Back to: Java and XSLT
© 2001, O'Reilly & Associates, Inc.
webmaster@oreilly.com